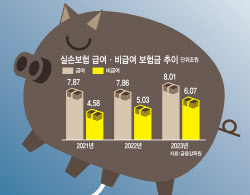
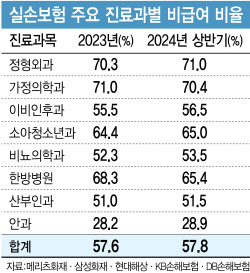
|

김동하 교수는 논문을 통해 ‘IOFM: Using the Interpolation Technique on the Over-Fitted Models to Identify Clean-Annotated Samples’로 딥러닝 모형을 이용한 데이터 정제 방법론을 제안해 연구 성과를 대내외적으로 인정받았다.
김 교수는 이번 연구를 통해 과적합 모형(Over-Fitted Models)을 활용해 학습 데이터에 포함된 오류 라벨 데이터를 정밀하게 정제할 수 있다는 것을 제안하고, 정밀한 실험을 통해 해당 방법론의 우수성을 이론적으로 입증했다. 특히 입력 공간과 과적합 모형의 은닉층 공간(Hidden layers)에서의 데이터 분포 특성을 이용해 오류 라벨 데이터를 구분할 수 있는 새로운 스코어를 개발했다는 점에서 학계의 주목을 받았다.
김동하 교수는 “최근 확산 모델(Diffusion Model), 거대언어모델(LLM)로 대표되는 대용량 딥러닝 모형이 폭발적인 관심을 받으면서 대량의 학습 데이터의 품질 관리 또한 중요한 문제로 대두되고 있다”며 “현재 이 분야의 관심이 높은 만큼 성신여대 교수진, 학생들과 함께 다양한 협력 연구를 진행해 양질의 연구 성과를 만들어가길 바란다”고 소감을 말했다.